Lecture Notes: NLP with Deep Learning - 1
What is the science behind ChatGPT? How can computers understand words? Word embedding and the Word2Vec algorithm are the starting blocks of NLP.


I can't believe it has been four years since I finished college. To my surprise, I missed taking courses just for the sake of science.
Working at a company, putting your knowledge and effort to build something is excellent and satisfying. You also gain experience by doing that.
But curiosity is a strong human motive to learn something new. I think the latest advances in AI and the hype around ChatGPT and language models triggered my curiosity.
So, I decided to take open lectures by Standford University on YouTube. I wanted to keep track of my learning progress and share my lecture notes in this series.
Meaning of a Word
Even though I used ChatGPT before, I didn't know the science behind it. It all looked like magic to me, as it does to most people.
In the first lecture, I got really excited to see how we can translate words into a machine-understandable format. The lesson started with the following comic:


The comic is a mind-opener that makes you question how you give meanings to words.
Language constantly evolves, there are new words entering our lives and some words stop being used and some words gain new meanings!
Moreover, the meaning of a word also changes depending on the context.
Word Embedding
Word embedding is a large dimensional ( hundreds of dimensions ) space made up of word vectors. A word vector is the mathematical representation of the meaning of a word.
I'll explain how scientists turn words into mathematics in a minute. But first, let's look at an extremely simplified two-dimensional representation of a word embedding:
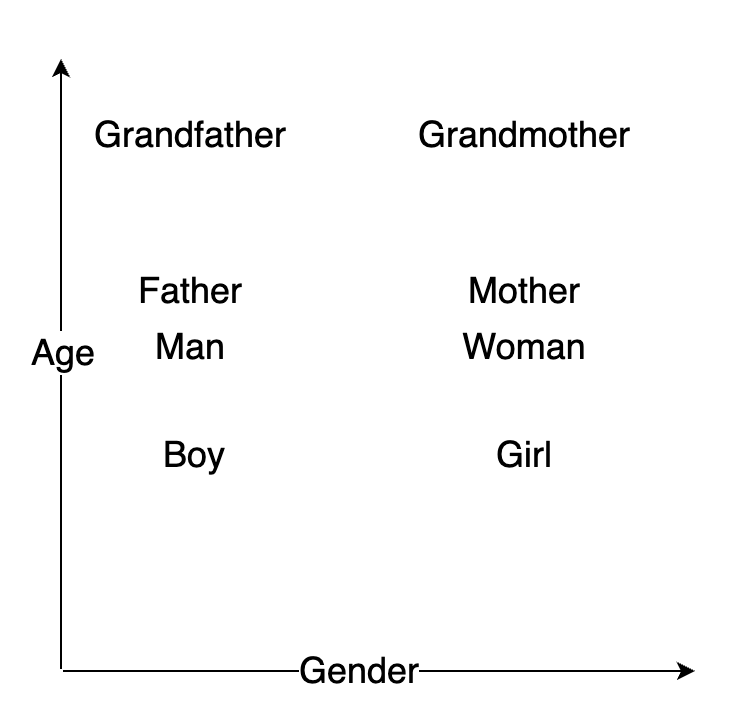
Of course, there are no labels such as age or gender in a real word embedding, because dimensions don't have to represent a specific thing.
The meaning of words is too broad to represent in a two-dimensional space. But having too many dimensions make the computation harder. A relatively sufficient word embedding can have 300 dimensions.
Even though we can't visualize a space with hundreds of dimensions in our heads, it is enough to understand why we need to have so many dimensions for representing words as vectors.
Word2Vec Algorithm
Word2Vec is one of the models you can use to translate words into a machine-readable format. Basically, it converts words into vectors.
I will try to explain how Word2Vec converts words into vectors, but honestly, the idea is all I can present to you. Because I didn't understand the mathematics behind it.
What do we want to achieve by converting a word to a vector? We want to create a word embedding in which semantically similar words are closer to each other.
The algorithm is based on the famous quote:
You shall know a word by the company it keeps. - John Rupert Firth
The Word2Vec algorithm takes a large corpus ( body ) of text as input. Then tries to assign vectors to every unique word in the text. The value of the vector is adjusted iteratively to create a probability function P.
P(c|o) = Probability of word o appear in the context of center word c
The probability function gives the probability of a word appearing in the context of another word. In each iteration, the vectors are adjusted and the probability function gives more accurate results.
The context words and the center word are defined as in the example:
This is a really big text input you give to the algorithm.
This is a really big text input you give to the algorithm.
This is a really big text input you give to the algorithm.
This is a really big text input you give to the algorithm.
At each step, a word is selected as the center word and words within a certain radius of the center word are context words.
If the above sentence is the only input you give to the algorithm, you expect the probability of the word "big" appearing in the context of "text" to be very high.
And with a large enough dataset, this algorithm can create a word embedding in which words are closer to each other if they are semantically similar.
Results: Analogy Example
At the end of the lecture, there is a fascinating use case example for the algorithm.
Since words are described as vectors via the Word2Vec algorithm, you can apply vector operations on words!
Firstly, you can ask the algorithm: "What are some similar words to the banana?". And the algorithm gives very accurate results such as "coconut, mongo, bananas".
Once those vectors are calculated, this is just a question of finding the nearest points on a k-dimensional space. This is easily answered by running the k-nearest neighbors - knn - algorithm on the word embedding.
Secondly, you can add or subtract words from each other!
In the lecture, the following example is given:
King - Man + Woman = ?
And the algorithm replied correctly with the Queen!
So, with this algorithm, you can find analogies very easily.
Summary
This was a great introduction lecture. If you have read it so far, I strongly suggest you go watch it on YouTube.
I will be sharing a post for each lecture on the list, so stay tuned!


